 電装工芸日記
- 舞台照明機器の製作とか -
電装工芸日記
- 舞台照明機器の製作とか -
2022年の投稿[394件](28ページ目)
2022年3月 この範囲を時系列順で読む この範囲をファイルに出力する
SPI-DMXを使うにはSPIに渡す配列に少し工夫が必要です。
レベル値の2次元配列[ユニバース,スロットアドレス]を1次元配列[スロットアドレス]に変換してSPIに渡すのですが、<ユニバースnのスロットx>を<n.x>と書くなら、
[<0.1>,<1.1>,<2.1>,・・・,<6.1>,<7.1>,<0.2>,<1.2>,<2.2>,・・・,<6.2>,<7.2>,
・・・,
<0.512>,<1.512>,<2.512>,・・・,<6.512>,<7.512>]
としなければなりません。[ユニバース,スロットアドレス]だったものを[スロットアドレス,ユニバース]の順番で1次元配列にするのです。
ちなみに元のスロットデータは
[[<0.1>,<0.2>,<0.3>,・・・,<0.512>],
[<1.1>,<1.2>,<1.3>,・・・,<1.512>],
・・・,
[<7.1>,<7.2>,<7.3>,・・・,<7.512>]]
こんな2次元配列です。
元のスロットデータをout_routeとし、SPIに渡すスロットデータをout_spi_arrayとするなら
out_spi_array = out_route.ravel( 'F' )
あれま、たった一行。
カッコ内の'F'はravelの動作モードを表すものらしい。
これまたPythonの繰り返しコマンドを用いずにnumpyだけで変換出来てしまった。
numpy素晴らしい。
#Python #[Art-Net]
レベル値の2次元配列[ユニバース,スロットアドレス]を1次元配列[スロットアドレス]に変換してSPIに渡すのですが、<ユニバースnのスロットx>を<n.x>と書くなら、
[<0.1>,<1.1>,<2.1>,・・・,<6.1>,<7.1>,<0.2>,<1.2>,<2.2>,・・・,<6.2>,<7.2>,
・・・,
<0.512>,<1.512>,<2.512>,・・・,<6.512>,<7.512>]
としなければなりません。[ユニバース,スロットアドレス]だったものを[スロットアドレス,ユニバース]の順番で1次元配列にするのです。
ちなみに元のスロットデータは
[[<0.1>,<0.2>,<0.3>,・・・,<0.512>],
[<1.1>,<1.2>,<1.3>,・・・,<1.512>],
・・・,
[<7.1>,<7.2>,<7.3>,・・・,<7.512>]]
こんな2次元配列です。
元のスロットデータをout_routeとし、SPIに渡すスロットデータをout_spi_arrayとするなら
out_spi_array = out_route.ravel( 'F' )
あれま、たった一行。
カッコ内の'F'はravelの動作モードを表すものらしい。
これまたPythonの繰り返しコマンドを用いずにnumpyだけで変換出来てしまった。
numpy素晴らしい。
#Python #[Art-Net]
回路図の最新版です。
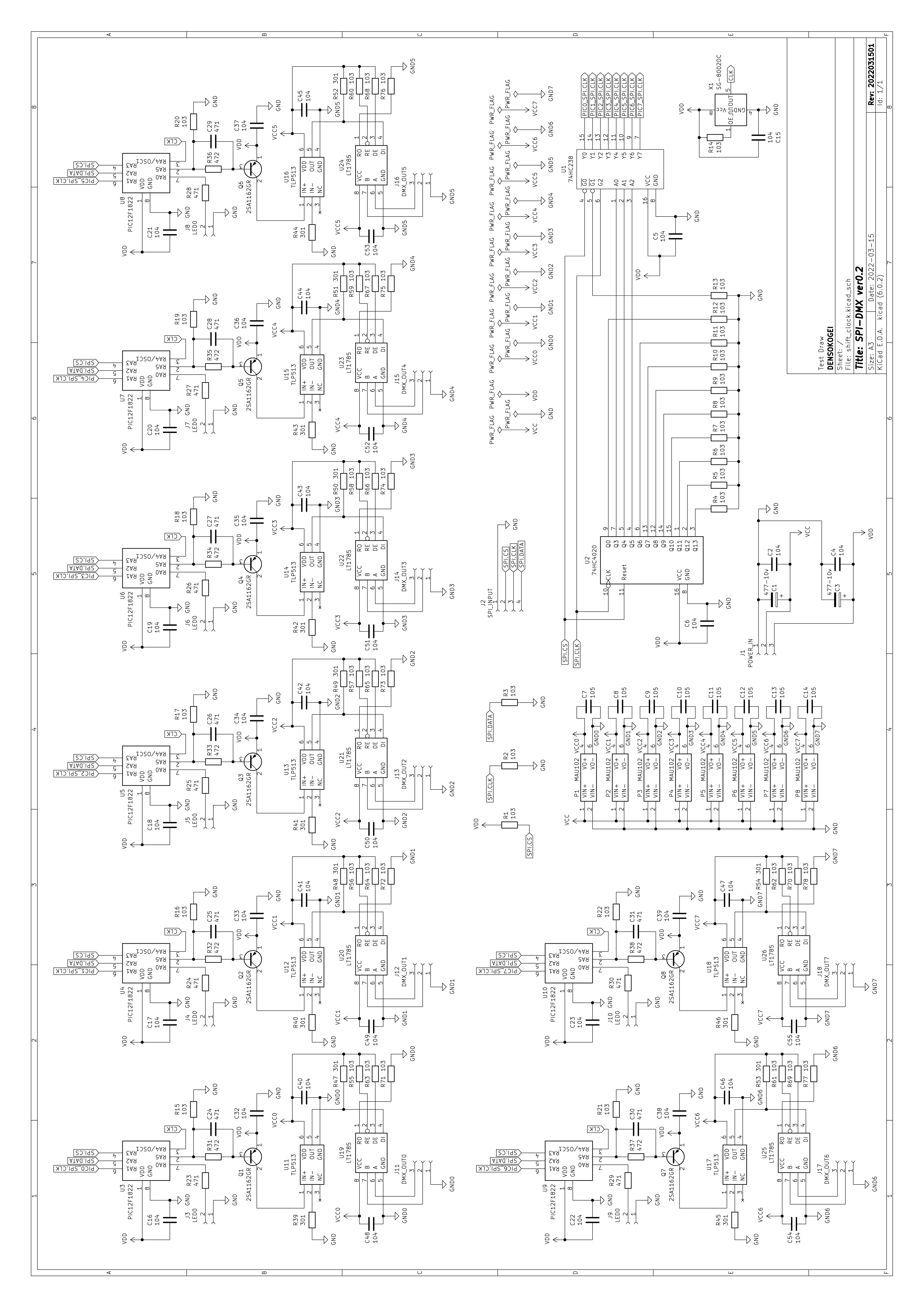
これで動いてくれたらいいのですけど・・・
#電子工作
今回の基板は大量のチップ部品が背面に付きます。これを手ハンダは避けたい。
基板と共にステンシルを頼んだのでリフローが出来ればいいけれど加熱台はどうする?
amazonさんにこんなんありました。

200 X 200mm LEDマイクロコンピューター電気ホットプレート予熱はんだ付け予熱ステーション、ウェルダーホットプレートリワークヒーターラボ110 / 220V AC 800W(美规110V)
カタログスペック的にはドストライクな製品ですが使えるのでしょうか。
中国から直送みたいで納期は4月上旬です。
この手の製品は国産の良い物だと10万近くするので避けていましたが1万円切るならアリでしょう。
家電のホットプレートを使う方法もありますが、この価格ならこっちの方がいいかも。天板平らだし。
たぶん設定と実際の温度は違うと思いますが、放射温度計を使って設定値に対する実際の温度を把握すれば使えるっしょ。
リフローは220度で60秒がペーストハンダメーカーの公称値です。ハンダの溶ける様を目の前に見られますから試してデータを取りましょう。220度ですと部品の耐久時間は長くないので、この辺りも調べておくべき課題です。
某メーカーさんの推奨値です。
プレヒート 130~180℃ 60~90sec.
リフロー 220℃以上 30~90sec.
ピーク温度 240~250℃ 10sec.以内
逆用途として肉焼けますね。
リフローに使えなかったら焼肉用にしましょう。
そういえば基板屋さんからメールがありました。「政府と交渉して稼働出来れば納期が短くなります」とのことです。
通常なら一週間以内に日本まで届くサービスですが、電力不足のために工場の稼働が輪番になっているのでしょう。
こればかりは仕方ありません。
#工具や資材
Fusion360で部品の3Dモデルを描いて追加してみました。
モデルをSTEP形式で書き出せばそのままKiCadに持っていけます。


3Dの基板をグルグルさせてもすぐに飽きますが、部品の干渉やシルク(文字印刷)のチェックには効果絶大。
#電子工作
モデルをSTEP形式で書き出せばそのままKiCadに持っていけます。
3Dの基板をグルグルさせてもすぐに飽きますが、部品の干渉やシルク(文字印刷)のチェックには効果絶大。
#電子工作
そんなワケでKiCadを使ってみたワケです。
慣れるとサクサク描けて良いCADだと思います。空き時間にユックリ習作しましたが思った通り描けます。
ただ、基板の寸法はインチ法とメートル法が混在するので、CAD云々以前にこの辺で混乱するかも。
#電子工作
慣れるとサクサク描けて良いCADだと思います。空き時間にユックリ習作しましたが思った通り描けます。
ただ、基板の寸法はインチ法とメートル法が混在するので、CAD云々以前にこの辺で混乱するかも。
#電子工作
どうにもソワソワしてしまうので、基板を発注までやってみました。
画像はKiCadによる完成イメージです。

本来ならブレッドボードなどで回路を隅々まで確認してから発注するべきですが、工程を一通り流し、仕上がりを確認するためのテスト発注です。
200x85mmと少し大きめの基板ですが、5枚で12,000円程度。10枚にしても+2,000円くらい。長くお世話になったp板.comさんには申し訳ないけど、価格が1/10では・・・
コロナの影響で少し時間がかかるそうですが、10日前後なので速いです。
ちなみこの基板、SPI入力のDMXドライバです。RaspberryPiからCSありのSPIを送るだけでレガシーDMXを8ユニバース出します。もちろんアイソレーションしてます。想定通りに動けば、ですけどね。
追記
価格は100x100mm以下なら1枚200円前後、50x50mm以下なら100円前後。感光基板で自作するより遥かに安い。試作段階でも気軽に使えます。
#電子工作
画像はKiCadによる完成イメージです。
本来ならブレッドボードなどで回路を隅々まで確認してから発注するべきですが、工程を一通り流し、仕上がりを確認するためのテスト発注です。
200x85mmと少し大きめの基板ですが、5枚で12,000円程度。10枚にしても+2,000円くらい。長くお世話になったp板.comさんには申し訳ないけど、価格が1/10では・・・
コロナの影響で少し時間がかかるそうですが、10日前後なので速いです。
ちなみこの基板、SPI入力のDMXドライバです。RaspberryPiからCSありのSPIを送るだけでレガシーDMXを8ユニバース出します。もちろんアイソレーションしてます。想定通りに動けば、ですけどね。
追記
価格は100x100mm以下なら1枚200円前後、50x50mm以下なら100円前後。感光基板で自作するより遥かに安い。試作段階でも気軽に使えます。
#電子工作
報道かくあるべしといった印象
当事者でない人が語る言葉でありますが、一般人には出来ない深読みの一つという意味で良いと思います。
今の報道の大半が子供っぽ過ぎるために印象に残っただけかもしれませんが・・・
#雑談
当事者でない人が語る言葉でありますが、一般人には出来ない深読みの一つという意味で良いと思います。
今の報道の大半が子供っぽ過ぎるために印象に残っただけかもしれませんが・・・
#雑談
KiCadの習作としてSPI-DMXの回路図を書いてみました。
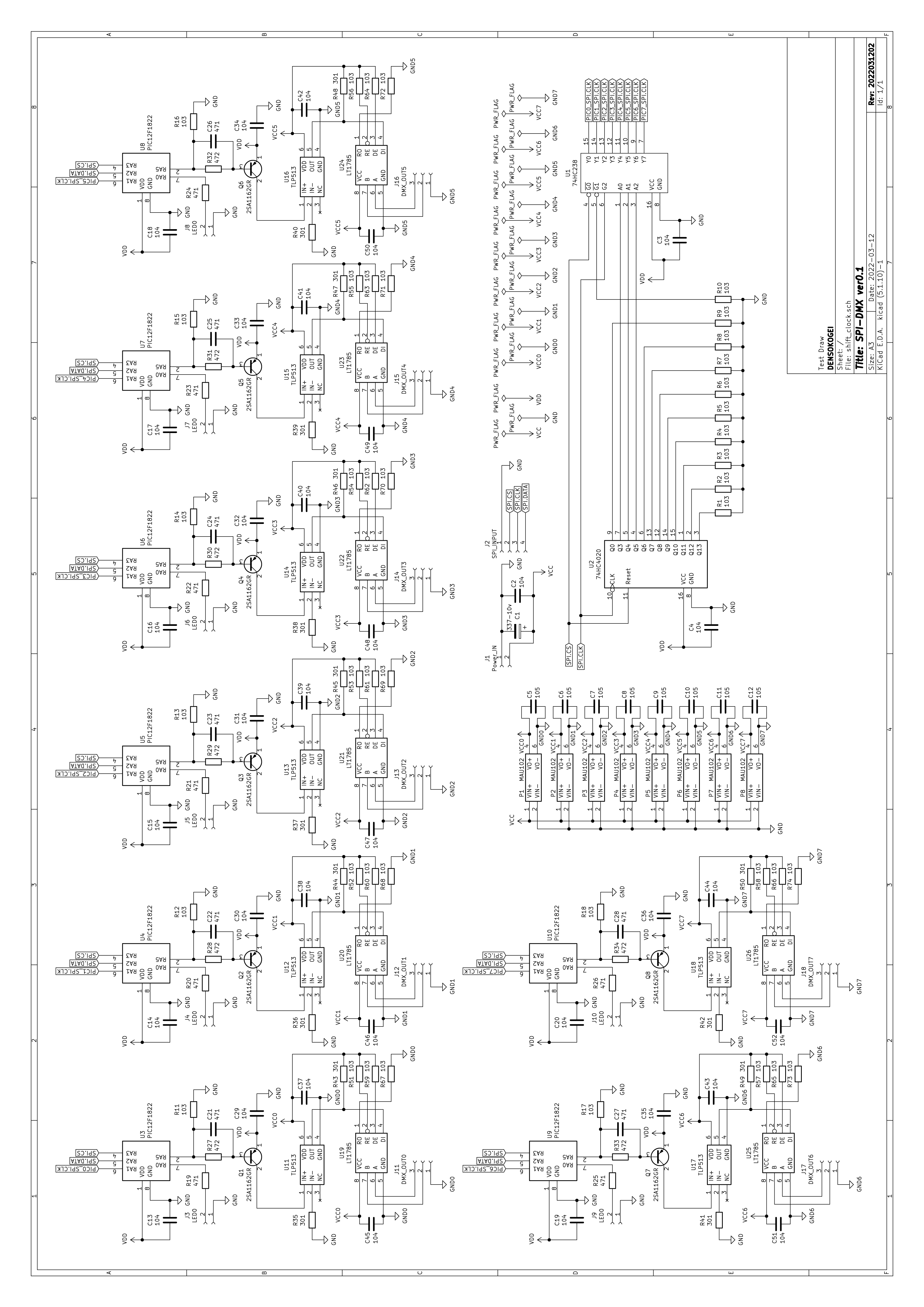
検証やら校正はこれからですが、ここまで書けたらいいしょ。
目的は図の清書ではなく、ネットリスト(部品と配線の情報)の生成です。
ちなみに、OE(OutEnable)とRESETはSPIのCSで構わないようです。
CSは負論理、OEは負論理、RESETは正論理です。CSは送信中はL、送信が終わって次が始まる少し前まではHです。
てことは、OEのロジックにもRESETのロジックにも合います。OEはSPI.CLKが出る少し前にLになって送信が終わればHになって欲しく、RESETは送信が終わったら即Hで送信が始まる少し前にLになって欲しいのでバッチリです。
仮組みして検証しないといけませんが、これでいいならSPIの3本だけで動くので望ましい状態です。
#電子工作
検証やら校正はこれからですが、ここまで書けたらいいしょ。
目的は図の清書ではなく、ネットリスト(部品と配線の情報)の生成です。
ちなみに、OE(OutEnable)とRESETはSPIのCSで構わないようです。
CSは負論理、OEは負論理、RESETは正論理です。CSは送信中はL、送信が終わって次が始まる少し前まではHです。
てことは、OEのロジックにもRESETのロジックにも合います。OEはSPI.CLKが出る少し前にLになって送信が終わればHになって欲しく、RESETは送信が終わったら即Hで送信が始まる少し前にLになって欲しいのでバッチリです。
仮組みして検証しないといけませんが、これでいいならSPIの3本だけで動くので望ましい状態です。
#電子工作
昨日から3日間、ホール管理の増員です。増員と言っても規定による員数合わせなので実働は毎日30分ほど。
ヒマっちゃヒマですが、リクエストが突然入ってくるので、頭を全振りする様な事は出来ません。
そんな時は調べものやお勉強がいい。今日の課題はプリント基板CADのKiCadです。
KiCadは以前ご紹介しましたが、フリーとは思えないほど良く出来たプリント基板CADです。回路図作成、基板デザイン、ガーバーデーターの出力まで一貫して作業出来ます。
プリント基板の製造を外注し始めた頃は手ごろなプリント基板CADが無かったのでp板.comさんのCADLUS-Xを使っていましたが、p板.comさんを含めプリント基板屋さんならどこでもガーバーデーターで受け付けてくれますので、KiCadに移行しようと勉強中なワケです。
#電子工作
ヒマっちゃヒマですが、リクエストが突然入ってくるので、頭を全振りする様な事は出来ません。
そんな時は調べものやお勉強がいい。今日の課題はプリント基板CADのKiCadです。
KiCadは以前ご紹介しましたが、フリーとは思えないほど良く出来たプリント基板CADです。回路図作成、基板デザイン、ガーバーデーターの出力まで一貫して作業出来ます。
プリント基板の製造を外注し始めた頃は手ごろなプリント基板CADが無かったのでp板.comさんのCADLUS-Xを使っていましたが、p板.comさんを含めプリント基板屋さんならどこでもガーバーデーターで受け付けてくれますので、KiCadに移行しようと勉強中なワケです。
#電子工作
Art-Netは入口の処理がまとまったので肝心のパッチ処理を考えています。
パッチとは入口と出口を1対多の関係で結びつける処理です。基本的な考え方は簡単ですがどう処理したものか。
と、言いますのも、処理の回数が多いので、1回1回の処理を限りなく軽くしないと間に合いません。
単純に考えればfor文を使ってスロット単位に移し替えをすればいいのですが、これではちょいと遅いようです。
何か無いかと調べたところnumpyに良い処理方法がありました。
「ファンシーインデックス」と呼ばれる方法です。
numpyの配列はインデックスで内容を参照できますが、インデックスに配列を使うことも出来、これを「ファンシーインデックス」と呼ぶようです。
パッチにおいては、出力側が参照する入口側のスロットのインデックスを配列にして使います(パッチマップ)。
一番単純な入力1ユニバース-出力1ユニバースを処理するとして、
入口側の配列が5スロットある場合
input = np.array( [ 11, 22, 30, 44, 50 ] )
とし、
これに対するパッチマップを
map = np.array( [ 0, 3, 4, 2, 2, 3, 1 ] )
とした場合、
patched_values = input[ map ] ※ 内部的には input[ [ 0, 3, 4, 2, 2, 3, 1 ] ] と同意
print( patched_values )
>>> [ 11 44 50 30 30 44 22 ]
インデックスの基底数がゼロなので注意が必要ですが、mapに記載されたインデックスでinputを参照し、配列としてoutputを得られます。
入力のスタック(input_stack)が[ delay, route, address ]の3次元配列の場合は、出力側スロット視点で次の3つの配列をインデックスにします。
delay_index_map:スロットごとのディレイレイヤーのインデックスを表すインデックスの配列 (取り扱いスロット数分・現在のカレントindexからオフセット済み)
※ delay_index_map = ( <ディレイレイヤーのスタック数> + <現在のカレントindex> - delay_map ) % <ディレイレイヤーのスタック数>
in_route_map:入力スロットのルートを表すインデックスの配列 (取り扱いスロット数分)
in_slot_map:入力スロットのアドレスを表すインデックスの配列 (取り扱いスロット数分)
※ in_route_mapとin_slot_mapを合わせてpatch_mapとなる。
とすると、
patched_values = input_stack[ [ delay_index_map, in_route_map, in_slot_map ] ]
patched_values は取り扱いスロット数分の1次元配列です。
ディレイの処理も含めて1行のコマンドで出力値を得られます。素晴らしい。
ここでスロットデータが1次元配列になるので、ここから先、出力ポートに渡すまではスロットを1本の通し番号で扱った方が良さそう。
同様の方法でカーブプロファイル変換も出来ます。
カーブプロファイル(curve_profile_values)を 変換後レベル値[ プロファイルナンバー, 元レベル値 ] 、カーブプロファイルマップ(curve_profile_map)をプロファイルナンバー[ スロットアドレス ]とし、変換した配列を curve_converted_values とすると。
curve_converted_values = curve_profile_values[ curve_profile_map, patched_values ]
※ len( curve_profile_map ) == len( patched_values ) がTrueなこと。
curve_converted_valuesを出力ルートとスロットアドレスの2次元配列にするなら、
output_values = curve_converted_values.reshape( <ルートの本数>, 512 )
※ <ルートの本数> × 512 = 取り扱いスロット総数 であること
コマンドが少ないから処理時間が短いとは限りませんが、少なくともfor文を用いた処理より軽いことは間違いありません。
numpy素晴らしい。
#Python #[Art-Net]
パッチとは入口と出口を1対多の関係で結びつける処理です。基本的な考え方は簡単ですがどう処理したものか。
と、言いますのも、処理の回数が多いので、1回1回の処理を限りなく軽くしないと間に合いません。
単純に考えればfor文を使ってスロット単位に移し替えをすればいいのですが、これではちょいと遅いようです。
何か無いかと調べたところnumpyに良い処理方法がありました。
「ファンシーインデックス」と呼ばれる方法です。
numpyの配列はインデックスで内容を参照できますが、インデックスに配列を使うことも出来、これを「ファンシーインデックス」と呼ぶようです。
パッチにおいては、出力側が参照する入口側のスロットのインデックスを配列にして使います(パッチマップ)。
一番単純な入力1ユニバース-出力1ユニバースを処理するとして、
入口側の配列が5スロットある場合
input = np.array( [ 11, 22, 30, 44, 50 ] )
とし、
これに対するパッチマップを
map = np.array( [ 0, 3, 4, 2, 2, 3, 1 ] )
とした場合、
patched_values = input[ map ] ※ 内部的には input[ [ 0, 3, 4, 2, 2, 3, 1 ] ] と同意
print( patched_values )
>>> [ 11 44 50 30 30 44 22 ]
インデックスの基底数がゼロなので注意が必要ですが、mapに記載されたインデックスでinputを参照し、配列としてoutputを得られます。
入力のスタック(input_stack)が[ delay, route, address ]の3次元配列の場合は、出力側スロット視点で次の3つの配列をインデックスにします。
delay_index_map:スロットごとのディレイレイヤーのインデックスを表すインデックスの配列 (取り扱いスロット数分・現在のカレントindexからオフセット済み)
※ delay_index_map = ( <ディレイレイヤーのスタック数> + <現在のカレントindex> - delay_map ) % <ディレイレイヤーのスタック数>
in_route_map:入力スロットのルートを表すインデックスの配列 (取り扱いスロット数分)
in_slot_map:入力スロットのアドレスを表すインデックスの配列 (取り扱いスロット数分)
※ in_route_mapとin_slot_mapを合わせてpatch_mapとなる。
とすると、
patched_values = input_stack[ [ delay_index_map, in_route_map, in_slot_map ] ]
patched_values は取り扱いスロット数分の1次元配列です。
ディレイの処理も含めて1行のコマンドで出力値を得られます。素晴らしい。
ここでスロットデータが1次元配列になるので、ここから先、出力ポートに渡すまではスロットを1本の通し番号で扱った方が良さそう。
同様の方法でカーブプロファイル変換も出来ます。
カーブプロファイル(curve_profile_values)を 変換後レベル値[ プロファイルナンバー, 元レベル値 ] 、カーブプロファイルマップ(curve_profile_map)をプロファイルナンバー[ スロットアドレス ]とし、変換した配列を curve_converted_values とすると。
curve_converted_values = curve_profile_values[ curve_profile_map, patched_values ]
※ len( curve_profile_map ) == len( patched_values ) がTrueなこと。
curve_converted_valuesを出力ルートとスロットアドレスの2次元配列にするなら、
output_values = curve_converted_values.reshape( <ルートの本数>, 512 )
※ <ルートの本数> × 512 = 取り扱いスロット総数 であること
コマンドが少ないから処理時間が短いとは限りませんが、少なくともfor文を用いた処理より軽いことは間違いありません。
numpy素晴らしい。
#Python #[Art-Net]