 電装工芸日記
- 舞台照明機器の製作とか -
電装工芸日記
- 舞台照明機器の製作とか -
2022年の投稿(時系列順)[394件](12ページ目)
2022年3月 この範囲を新しい順で読む この範囲をファイルに出力する
SPIでレガシーDMXを出力する回路の基本要素は揃いました。PICをプログラムして実験する段階です。
本業が忙しくなってしまったので棚上げですが、PICの基本設計は進めましょう。
PICは12F1822を使います。PIC12とありますが、PIC16系の8ピン版と思っていい製品です。
ピンアサインは次の通りです。
拡張ミッドレンジPICにはモジュールのアサインピンをある程度切り替えられる機能があります。
TRISとはI/Oピンの入出力方向を設定する要素です。
VDD
VSS(GND)
RA0 TX_Pilot_LED TRIS-OUTPUT(汎用I/Oとして使い、送信が行われるとLEDを点灯させます)
RA1 SPI.SCK TRIS-INPUT
RA2 SPI.SDI TRIS-INPUT
RA3 DMX.RESET TRIS-INPUT
RA4 USART.TX TRIS-OUTPUT(ただし、BreakTimeを作るためにINPUTにすることがあります)
RA5 CSC1 TRIS-INPUT(クロックの設定は優先順位が高いので、TRISはどちらでも機能します)
これには隠れたコツがあります。
SPIを使うならSPI.SDOがあります。使わないI/Oですがどこかにアサインしなければなりませんので、USART.TXと同じRA4にアサインします。被って出力がおかしくなりそうですが、SPIよりも優先順位が高いUSART.TXが出力されますから大丈夫。逆だったら困りましたけどね。
クロック発信子にはクリスタルオシレータ(8MHz)SG-8002DC(3.3V)を使います。普段はPIC1個に対し水晶発振子を1個使うのですが、今回は同じクロックレートで動く複数のPICを1枚の基板に載せますので、部品点数を減らす意味も含めてこれを使います。PICのI/Oピンも減るし。
#電子工作
本業が忙しくなってしまったので棚上げですが、PICの基本設計は進めましょう。
PICは12F1822を使います。PIC12とありますが、PIC16系の8ピン版と思っていい製品です。
ピンアサインは次の通りです。
拡張ミッドレンジPICにはモジュールのアサインピンをある程度切り替えられる機能があります。
TRISとはI/Oピンの入出力方向を設定する要素です。
VDD
VSS(GND)
RA0 TX_Pilot_LED TRIS-OUTPUT(汎用I/Oとして使い、送信が行われるとLEDを点灯させます)
RA1 SPI.SCK TRIS-INPUT
RA2 SPI.SDI TRIS-INPUT
RA3 DMX.RESET TRIS-INPUT
RA4 USART.TX TRIS-OUTPUT(ただし、BreakTimeを作るためにINPUTにすることがあります)
RA5 CSC1 TRIS-INPUT(クロックの設定は優先順位が高いので、TRISはどちらでも機能します)
これには隠れたコツがあります。
SPIを使うならSPI.SDOがあります。使わないI/Oですがどこかにアサインしなければなりませんので、USART.TXと同じRA4にアサインします。被って出力がおかしくなりそうですが、SPIよりも優先順位が高いUSART.TXが出力されますから大丈夫。逆だったら困りましたけどね。
クロック発信子にはクリスタルオシレータ(8MHz)SG-8002DC(3.3V)を使います。普段はPIC1個に対し水晶発振子を1個使うのですが、今回は同じクロックレートで動く複数のPICを1枚の基板に載せますので、部品点数を減らす意味も含めてこれを使います。PICのI/Oピンも減るし。
#電子工作
PICでDMX512を出力する際、面倒なのがBreakTimeです。
一般的なUARTでDMX512の様に長いBreakTimeが使われることは無いためか、PICにはそのような機能がありません。何らかのチカラ技で作らないといけません。
私が最終的にたどり着いた方法は、
1)USARTが出力されるI/Oピンをプルダウンしてアイドル・ローにしておく。
2)BreakTimeは0x00の空送信で作る。ただし、0x00送信でもStopBit(H)が発生するので、以下(3)の方法で消す。
3)BreakTimeの空送信が始まってからStopBitが始まるまでの間(Lが続く間)にTRIS(I/Oピンの入出力方向を決めるフラグ)を入力に切り替える。入力にするとI/Oピンがハイインピーダンス(Z)になり、プルダウンされているためRS485ドライバに届く信号はLを維持する。
4)BreakTimeの時間に相当する空送信する。
5)BreakTimeの終わりというか次のフレームの送信開始前に0x00を送信してTRISを出力に切り替える。0x00送信のStopBitがMarkAfterBreakとなる。ただ、MarkAfterBreakは少し長い方が安定するので、0xCO(b11000000)などのMSB詰めの数値を使ってMarkAfterBreakを長くしてもいい。
といった内容です。
これならタイマー処理をせずにBreakTimeを作れます。
BreakTimeを表すデータをBreakTimeZero、BreakTimeZeroの始まりのバイトをBreakTimeNose、最後をBreakTimeTailと勝手に呼んでますが、RaspberryPiからのSPIデータをBreakTimeTailから始まるモノにしておけばPIC側の処理は凄く簡単です。
0)RaspberryPiからRESET信号(実際にはCSを用いる)をPICに送り、PICはこれを見て送信カウンタをクリアしてUSART.TXピンのTRISを入力に切り替えておく。アイドル・ロー。
1)SPIの最初のバイト(BreakTimeTail)を受信したら、USARTに渡して送信し、3bit分待ってからUSART.TXピンのTRISを出力に切り替える。以下、受信値を1バイト送信するごとに送信カウンタをインクリメントする。
2)512スロットを送信した後のバイトはBreakTimeNoseになる。ただ、PICのUSARTは1ワード分のキャッシュを持っているので、BreakTimeZeroの2バイト目をUSARTに渡した後(BreakTimeNoseが送信開始された後)、3bit分待ってからTRISを入力に切り替えてBrakTimeとする。送信制御は送信カウンタを用いる。
3)以下、SPIのデータが終了(RaspberryPiからのCSで確認)したら、送信カウンタをクリアしてSPIを受信待機にする。=>(1)に戻る。
4)BreakTimeZeroを送信する前にSPIが終わってしまったらエラー。TRISを入力に切り替えてBrakTimeにしておくなど、エラー処理を行う。
5)TRISの切り替えの前に3bit分待つのは、次の送信バイトの受け入れがStopBit中に可能になるからです。
こんな感じかな。
#電子工作
一般的なUARTでDMX512の様に長いBreakTimeが使われることは無いためか、PICにはそのような機能がありません。何らかのチカラ技で作らないといけません。
私が最終的にたどり着いた方法は、
1)USARTが出力されるI/Oピンをプルダウンしてアイドル・ローにしておく。
2)BreakTimeは0x00の空送信で作る。ただし、0x00送信でもStopBit(H)が発生するので、以下(3)の方法で消す。
3)BreakTimeの空送信が始まってからStopBitが始まるまでの間(Lが続く間)にTRIS(I/Oピンの入出力方向を決めるフラグ)を入力に切り替える。入力にするとI/Oピンがハイインピーダンス(Z)になり、プルダウンされているためRS485ドライバに届く信号はLを維持する。
4)BreakTimeの時間に相当する空送信する。
5)BreakTimeの終わりというか次のフレームの送信開始前に0x00を送信してTRISを出力に切り替える。0x00送信のStopBitがMarkAfterBreakとなる。ただ、MarkAfterBreakは少し長い方が安定するので、0xCO(b11000000)などのMSB詰めの数値を使ってMarkAfterBreakを長くしてもいい。
といった内容です。
これならタイマー処理をせずにBreakTimeを作れます。
BreakTimeを表すデータをBreakTimeZero、BreakTimeZeroの始まりのバイトをBreakTimeNose、最後をBreakTimeTailと勝手に呼んでますが、RaspberryPiからのSPIデータをBreakTimeTailから始まるモノにしておけばPIC側の処理は凄く簡単です。
0)RaspberryPiからRESET信号(実際にはCSを用いる)をPICに送り、PICはこれを見て送信カウンタをクリアしてUSART.TXピンのTRISを入力に切り替えておく。アイドル・ロー。
1)SPIの最初のバイト(BreakTimeTail)を受信したら、USARTに渡して送信し、3bit分待ってからUSART.TXピンのTRISを出力に切り替える。以下、受信値を1バイト送信するごとに送信カウンタをインクリメントする。
2)512スロットを送信した後のバイトはBreakTimeNoseになる。ただ、PICのUSARTは1ワード分のキャッシュを持っているので、BreakTimeZeroの2バイト目をUSARTに渡した後(BreakTimeNoseが送信開始された後)、3bit分待ってからTRISを入力に切り替えてBrakTimeとする。送信制御は送信カウンタを用いる。
3)以下、SPIのデータが終了(RaspberryPiからのCSで確認)したら、送信カウンタをクリアしてSPIを受信待機にする。=>(1)に戻る。
4)BreakTimeZeroを送信する前にSPIが終わってしまったらエラー。TRISを入力に切り替えてBrakTimeにしておくなど、エラー処理を行う。
5)TRISの切り替えの前に3bit分待つのは、次の送信バイトの受け入れがStopBit中に可能になるからです。
こんな感じかな。
#電子工作
Art-Netを受信した後、送信元別だった受信値をミックス(HTP)する方法。
numpy.maxを用いれば簡単
受信値を3次元のnumpy.arrayで保存します。
3次元のnumpy.arrayはエクセルでイメージするとわかりやすいかなと。
1スロットの受信値は0-255の数値で、これが横方向(行)に512個並んだ状態をユニバースとします。
これをルート別に縦方向(列)で並べます。ここまでは縦横の1枚のシートです。
この1枚を送信元別のシートとし、レイヤーとして重ねます。もちろん、スロットアドレスとルートは同様にします。
あとはレイヤーを串刺しで最大値を得ればHTPでミックスしたルートとスロットの2次元のnumpu.arrayを得られます。
numpyをnpの名前でimportし、3次元のnumpy.arrayをan_cache_senders_route、最大値の2次元のnumpy.arrayをan_cache_htpとすると次の様になります。
an_cache_htp = np.max( an_cache_senders_route, axis=0 )
こんな感じの1行で計算出来ます。axis=0は最大値を得る次元方向の指示です。3次元なら、axis=2は横で、axis=1は縦で、axis=0は奥行という指示です。
以下、ちょいとオレメモ
受信値、付随するデータ
an_bytes 受信したArt-Netパケットのデータ(type=bytes、別途デコード必要)
an_sender_ipaddress 受信したArt-Netパケットの送信元IPアドレス(type=string、4つのドット切り10進数 IPv4の一般的な表記)
an_received_datetime 受信された時点でdatetime.datetime.now()により取得した日時(type=datetime.datetime)
処理の処理を指示するデータ
an_universes2route 対象ユニバースの1次元配列 ( Net, Subnet, Universe )[ ルート ]
受信値を処理、管理するデータ
an_ipaddress_senders 送信元のIPアドレスの1次元配列 IPアドレス [ 送信元 ]
an_datetime_senders 送信元ごとの最終受信日時の1次元配列 最終受信日時 [ 送信元 ]
an_datetime_senders_route 送信元ごとにルートの最終受信日時の2次元配列 最終受信日時 [ 送信元, ルート ]
an_cache_senders_route 送信元とルートごとに受信値を保存する3次元配列 受信値 [ 送信元, ルート, スロットアドレス ]
an_cache_htp 次の処理へ渡す処理済み受信値の2次元配列 受信値 [ ルート, スロットアドレス ]
※ [ ]内はインデックスの要素([3次元目,2次元目,1次元目])
※ 同名のindexは同じ値になるように設定
#an_ipaddress_senders から an_sender_ipaddress と同じIPアドレスを持つ[ 送信元 ]のindex配列を得る
list( zip( *np.where( an_ipaddress_senders == an_sender_ipaddress ) ) )
※ 受信した際に重複しない様に送信元情報を保存してインデックスを発行し、送信元別に日時と受信値を保存するために使う。
※ ただし、対象のユニバースを送って来ない送信元は無いものとする。早い段階でフィルタしないと後が面倒。
#an_datetime_senders から現在日時より1秒以上前の日時を持つ[ 送信元 ]のindexの配列を得る
list( zip( *np.where( an_datetime_senders < ( datetime.datetime.now() - datetime.timedelta( seconds=1 ) ) ) ) )
※ 送信元の存在を確認するために使う。1秒間受信が無い送信元は無いものとする。
#an_datetime_senders_route から現在日時より1秒以上前の日時を持つ[ 送信元, ルート ]のindexの配列を得る
list( zip( *np.where( an_datetime_senders_route < ( datetime.datetime.now() - datetime.timedelta( seconds=1 ) ) ) ) )
※ ユニバースの存在を確認するために使う。1秒間受信が無いユニバース(=送信元,ルート)はゼロデータにする。
#Python #[Art-Net]
numpy.maxを用いれば簡単
受信値を3次元のnumpy.arrayで保存します。
3次元のnumpy.arrayはエクセルでイメージするとわかりやすいかなと。
1スロットの受信値は0-255の数値で、これが横方向(行)に512個並んだ状態をユニバースとします。
これをルート別に縦方向(列)で並べます。ここまでは縦横の1枚のシートです。
この1枚を送信元別のシートとし、レイヤーとして重ねます。もちろん、スロットアドレスとルートは同様にします。
あとはレイヤーを串刺しで最大値を得ればHTPでミックスしたルートとスロットの2次元のnumpu.arrayを得られます。
numpyをnpの名前でimportし、3次元のnumpy.arrayをan_cache_senders_route、最大値の2次元のnumpy.arrayをan_cache_htpとすると次の様になります。
an_cache_htp = np.max( an_cache_senders_route, axis=0 )
こんな感じの1行で計算出来ます。axis=0は最大値を得る次元方向の指示です。3次元なら、axis=2は横で、axis=1は縦で、axis=0は奥行という指示です。
以下、ちょいとオレメモ
受信値、付随するデータ
an_bytes 受信したArt-Netパケットのデータ(type=bytes、別途デコード必要)
an_sender_ipaddress 受信したArt-Netパケットの送信元IPアドレス(type=string、4つのドット切り10進数 IPv4の一般的な表記)
an_received_datetime 受信された時点でdatetime.datetime.now()により取得した日時(type=datetime.datetime)
処理の処理を指示するデータ
an_universes2route 対象ユニバースの1次元配列 ( Net, Subnet, Universe )[ ルート ]
受信値を処理、管理するデータ
an_ipaddress_senders 送信元のIPアドレスの1次元配列 IPアドレス [ 送信元 ]
an_datetime_senders 送信元ごとの最終受信日時の1次元配列 最終受信日時 [ 送信元 ]
an_datetime_senders_route 送信元ごとにルートの最終受信日時の2次元配列 最終受信日時 [ 送信元, ルート ]
an_cache_senders_route 送信元とルートごとに受信値を保存する3次元配列 受信値 [ 送信元, ルート, スロットアドレス ]
an_cache_htp 次の処理へ渡す処理済み受信値の2次元配列 受信値 [ ルート, スロットアドレス ]
※ [ ]内はインデックスの要素([3次元目,2次元目,1次元目])
※ 同名のindexは同じ値になるように設定
#an_ipaddress_senders から an_sender_ipaddress と同じIPアドレスを持つ[ 送信元 ]のindex配列を得る
list( zip( *np.where( an_ipaddress_senders == an_sender_ipaddress ) ) )
※ 受信した際に重複しない様に送信元情報を保存してインデックスを発行し、送信元別に日時と受信値を保存するために使う。
※ ただし、対象のユニバースを送って来ない送信元は無いものとする。早い段階でフィルタしないと後が面倒。
#an_datetime_senders から現在日時より1秒以上前の日時を持つ[ 送信元 ]のindexの配列を得る
list( zip( *np.where( an_datetime_senders < ( datetime.datetime.now() - datetime.timedelta( seconds=1 ) ) ) ) )
※ 送信元の存在を確認するために使う。1秒間受信が無い送信元は無いものとする。
#an_datetime_senders_route から現在日時より1秒以上前の日時を持つ[ 送信元, ルート ]のindexの配列を得る
list( zip( *np.where( an_datetime_senders_route < ( datetime.datetime.now() - datetime.timedelta( seconds=1 ) ) ) ) )
※ ユニバースの存在を確認するために使う。1秒間受信が無いユニバース(=送信元,ルート)はゼロデータにする。
#Python #[Art-Net]
Art-Netを受信してから一時保存する流れ
● Art-Netの受信・・・タイムアウトしたらすべての受信情報を初期化する
● 受信日時の取得
● 受信したバイナリをデコード
● 対象ユニバースか確認
● ルートIDを取得
● 送信元のIDを取得・新規送信元なら保存し送信元IDを取得
● 送信元の最終受信日時を上書き保存
● 送信元,ルートの最終受信日時を上書き保存
● 送信元,ルートで受信値を上書き保存(必ず512スロットで保存)
タイムアウト処理・・・0.2~0.5秒毎
● 送信元のタイムアウトを確認・・・タイムアウトしていたら送信元からの受信情報を初期化する
● ユニバースのタイムアウトを確認・・・タイムアウトしていたらユニバースをゼロデータにする
次工程からの読み出し要求への返信
● 送信元,ルートで保存した受信値から最大値を取り出す
● 返信
といった感じで、細かいコマンド処理とアルゴリズムが見えてきましたが、本業が忙しくなってソースを書くことが出来ません。
#Python #[Art-Net]
● Art-Netの受信・・・タイムアウトしたらすべての受信情報を初期化する
● 受信日時の取得
● 受信したバイナリをデコード
● 対象ユニバースか確認
● ルートIDを取得
● 送信元のIDを取得・新規送信元なら保存し送信元IDを取得
● 送信元の最終受信日時を上書き保存
● 送信元,ルートの最終受信日時を上書き保存
● 送信元,ルートで受信値を上書き保存(必ず512スロットで保存)
タイムアウト処理・・・0.2~0.5秒毎
● 送信元のタイムアウトを確認・・・タイムアウトしていたら送信元からの受信情報を初期化する
● ユニバースのタイムアウトを確認・・・タイムアウトしていたらユニバースをゼロデータにする
次工程からの読み出し要求への返信
● 送信元,ルートで保存した受信値から最大値を取り出す
● 返信
といった感じで、細かいコマンド処理とアルゴリズムが見えてきましたが、本業が忙しくなってソースを書くことが出来ません。
#Python #[Art-Net]
Art-Netは入口の処理がまとまったので肝心のパッチ処理を考えています。
パッチとは入口と出口を1対多の関係で結びつける処理です。基本的な考え方は簡単ですがどう処理したものか。
と、言いますのも、処理の回数が多いので、1回1回の処理を限りなく軽くしないと間に合いません。
単純に考えればfor文を使ってスロット単位に移し替えをすればいいのですが、これではちょいと遅いようです。
何か無いかと調べたところnumpyに良い処理方法がありました。
「ファンシーインデックス」と呼ばれる方法です。
numpyの配列はインデックスで内容を参照できますが、インデックスに配列を使うことも出来、これを「ファンシーインデックス」と呼ぶようです。
パッチにおいては、出力側が参照する入口側のスロットのインデックスを配列にして使います(パッチマップ)。
一番単純な入力1ユニバース-出力1ユニバースを処理するとして、
入口側の配列が5スロットある場合
input = np.array( [ 11, 22, 30, 44, 50 ] )
とし、
これに対するパッチマップを
map = np.array( [ 0, 3, 4, 2, 2, 3, 1 ] )
とした場合、
patched_values = input[ map ] ※ 内部的には input[ [ 0, 3, 4, 2, 2, 3, 1 ] ] と同意
print( patched_values )
>>> [ 11 44 50 30 30 44 22 ]
インデックスの基底数がゼロなので注意が必要ですが、mapに記載されたインデックスでinputを参照し、配列としてoutputを得られます。
入力のスタック(input_stack)が[ delay, route, address ]の3次元配列の場合は、出力側スロット視点で次の3つの配列をインデックスにします。
delay_index_map:スロットごとのディレイレイヤーのインデックスを表すインデックスの配列 (取り扱いスロット数分・現在のカレントindexからオフセット済み)
※ delay_index_map = ( <ディレイレイヤーのスタック数> + <現在のカレントindex> - delay_map ) % <ディレイレイヤーのスタック数>
in_route_map:入力スロットのルートを表すインデックスの配列 (取り扱いスロット数分)
in_slot_map:入力スロットのアドレスを表すインデックスの配列 (取り扱いスロット数分)
※ in_route_mapとin_slot_mapを合わせてpatch_mapとなる。
とすると、
patched_values = input_stack[ [ delay_index_map, in_route_map, in_slot_map ] ]
patched_values は取り扱いスロット数分の1次元配列です。
ディレイの処理も含めて1行のコマンドで出力値を得られます。素晴らしい。
ここでスロットデータが1次元配列になるので、ここから先、出力ポートに渡すまではスロットを1本の通し番号で扱った方が良さそう。
同様の方法でカーブプロファイル変換も出来ます。
カーブプロファイル(curve_profile_values)を 変換後レベル値[ プロファイルナンバー, 元レベル値 ] 、カーブプロファイルマップ(curve_profile_map)をプロファイルナンバー[ スロットアドレス ]とし、変換した配列を curve_converted_values とすると。
curve_converted_values = curve_profile_values[ curve_profile_map, patched_values ]
※ len( curve_profile_map ) == len( patched_values ) がTrueなこと。
curve_converted_valuesを出力ルートとスロットアドレスの2次元配列にするなら、
output_values = curve_converted_values.reshape( <ルートの本数>, 512 )
※ <ルートの本数> × 512 = 取り扱いスロット総数 であること
コマンドが少ないから処理時間が短いとは限りませんが、少なくともfor文を用いた処理より軽いことは間違いありません。
numpy素晴らしい。
#Python #[Art-Net]
パッチとは入口と出口を1対多の関係で結びつける処理です。基本的な考え方は簡単ですがどう処理したものか。
と、言いますのも、処理の回数が多いので、1回1回の処理を限りなく軽くしないと間に合いません。
単純に考えればfor文を使ってスロット単位に移し替えをすればいいのですが、これではちょいと遅いようです。
何か無いかと調べたところnumpyに良い処理方法がありました。
「ファンシーインデックス」と呼ばれる方法です。
numpyの配列はインデックスで内容を参照できますが、インデックスに配列を使うことも出来、これを「ファンシーインデックス」と呼ぶようです。
パッチにおいては、出力側が参照する入口側のスロットのインデックスを配列にして使います(パッチマップ)。
一番単純な入力1ユニバース-出力1ユニバースを処理するとして、
入口側の配列が5スロットある場合
input = np.array( [ 11, 22, 30, 44, 50 ] )
とし、
これに対するパッチマップを
map = np.array( [ 0, 3, 4, 2, 2, 3, 1 ] )
とした場合、
patched_values = input[ map ] ※ 内部的には input[ [ 0, 3, 4, 2, 2, 3, 1 ] ] と同意
print( patched_values )
>>> [ 11 44 50 30 30 44 22 ]
インデックスの基底数がゼロなので注意が必要ですが、mapに記載されたインデックスでinputを参照し、配列としてoutputを得られます。
入力のスタック(input_stack)が[ delay, route, address ]の3次元配列の場合は、出力側スロット視点で次の3つの配列をインデックスにします。
delay_index_map:スロットごとのディレイレイヤーのインデックスを表すインデックスの配列 (取り扱いスロット数分・現在のカレントindexからオフセット済み)
※ delay_index_map = ( <ディレイレイヤーのスタック数> + <現在のカレントindex> - delay_map ) % <ディレイレイヤーのスタック数>
in_route_map:入力スロットのルートを表すインデックスの配列 (取り扱いスロット数分)
in_slot_map:入力スロットのアドレスを表すインデックスの配列 (取り扱いスロット数分)
※ in_route_mapとin_slot_mapを合わせてpatch_mapとなる。
とすると、
patched_values = input_stack[ [ delay_index_map, in_route_map, in_slot_map ] ]
patched_values は取り扱いスロット数分の1次元配列です。
ディレイの処理も含めて1行のコマンドで出力値を得られます。素晴らしい。
ここでスロットデータが1次元配列になるので、ここから先、出力ポートに渡すまではスロットを1本の通し番号で扱った方が良さそう。
同様の方法でカーブプロファイル変換も出来ます。
カーブプロファイル(curve_profile_values)を 変換後レベル値[ プロファイルナンバー, 元レベル値 ] 、カーブプロファイルマップ(curve_profile_map)をプロファイルナンバー[ スロットアドレス ]とし、変換した配列を curve_converted_values とすると。
curve_converted_values = curve_profile_values[ curve_profile_map, patched_values ]
※ len( curve_profile_map ) == len( patched_values ) がTrueなこと。
curve_converted_valuesを出力ルートとスロットアドレスの2次元配列にするなら、
output_values = curve_converted_values.reshape( <ルートの本数>, 512 )
※ <ルートの本数> × 512 = 取り扱いスロット総数 であること
コマンドが少ないから処理時間が短いとは限りませんが、少なくともfor文を用いた処理より軽いことは間違いありません。
numpy素晴らしい。
#Python #[Art-Net]
昨日から3日間、ホール管理の増員です。増員と言っても規定による員数合わせなので実働は毎日30分ほど。
ヒマっちゃヒマですが、リクエストが突然入ってくるので、頭を全振りする様な事は出来ません。
そんな時は調べものやお勉強がいい。今日の課題はプリント基板CADのKiCadです。
KiCadは以前ご紹介しましたが、フリーとは思えないほど良く出来たプリント基板CADです。回路図作成、基板デザイン、ガーバーデーターの出力まで一貫して作業出来ます。
プリント基板の製造を外注し始めた頃は手ごろなプリント基板CADが無かったのでp板.comさんのCADLUS-Xを使っていましたが、p板.comさんを含めプリント基板屋さんならどこでもガーバーデーターで受け付けてくれますので、KiCadに移行しようと勉強中なワケです。
#電子工作
ヒマっちゃヒマですが、リクエストが突然入ってくるので、頭を全振りする様な事は出来ません。
そんな時は調べものやお勉強がいい。今日の課題はプリント基板CADのKiCadです。
KiCadは以前ご紹介しましたが、フリーとは思えないほど良く出来たプリント基板CADです。回路図作成、基板デザイン、ガーバーデーターの出力まで一貫して作業出来ます。
プリント基板の製造を外注し始めた頃は手ごろなプリント基板CADが無かったのでp板.comさんのCADLUS-Xを使っていましたが、p板.comさんを含めプリント基板屋さんならどこでもガーバーデーターで受け付けてくれますので、KiCadに移行しようと勉強中なワケです。
#電子工作
KiCadの習作としてSPI-DMXの回路図を書いてみました。
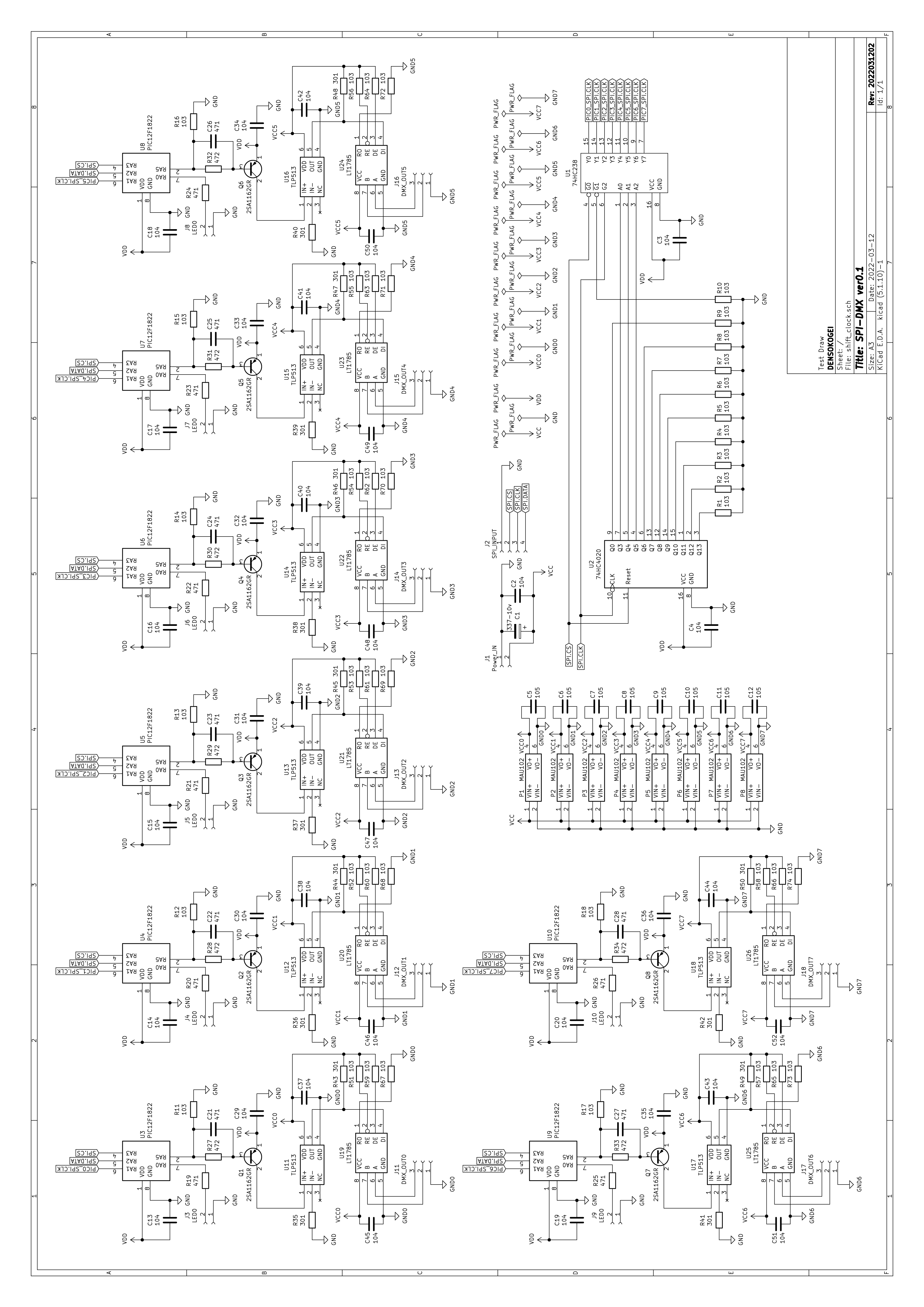
検証やら校正はこれからですが、ここまで書けたらいいしょ。
目的は図の清書ではなく、ネットリスト(部品と配線の情報)の生成です。
ちなみに、OE(OutEnable)とRESETはSPIのCSで構わないようです。
CSは負論理、OEは負論理、RESETは正論理です。CSは送信中はL、送信が終わって次が始まる少し前まではHです。
てことは、OEのロジックにもRESETのロジックにも合います。OEはSPI.CLKが出る少し前にLになって送信が終わればHになって欲しく、RESETは送信が終わったら即Hで送信が始まる少し前にLになって欲しいのでバッチリです。
仮組みして検証しないといけませんが、これでいいならSPIの3本だけで動くので望ましい状態です。
#電子工作
検証やら校正はこれからですが、ここまで書けたらいいしょ。
目的は図の清書ではなく、ネットリスト(部品と配線の情報)の生成です。
ちなみに、OE(OutEnable)とRESETはSPIのCSで構わないようです。
CSは負論理、OEは負論理、RESETは正論理です。CSは送信中はL、送信が終わって次が始まる少し前まではHです。
てことは、OEのロジックにもRESETのロジックにも合います。OEはSPI.CLKが出る少し前にLになって送信が終わればHになって欲しく、RESETは送信が終わったら即Hで送信が始まる少し前にLになって欲しいのでバッチリです。
仮組みして検証しないといけませんが、これでいいならSPIの3本だけで動くので望ましい状態です。
#電子工作
報道かくあるべしといった印象
当事者でない人が語る言葉でありますが、一般人には出来ない深読みの一つという意味で良いと思います。
今の報道の大半が子供っぽ過ぎるために印象に残っただけかもしれませんが・・・
#雑談
当事者でない人が語る言葉でありますが、一般人には出来ない深読みの一つという意味で良いと思います。
今の報道の大半が子供っぽ過ぎるために印象に残っただけかもしれませんが・・・
#雑談
どうにもソワソワしてしまうので、基板を発注までやってみました。
画像はKiCadによる完成イメージです。

本来ならブレッドボードなどで回路を隅々まで確認してから発注するべきですが、工程を一通り流し、仕上がりを確認するためのテスト発注です。
200x85mmと少し大きめの基板ですが、5枚で12,000円程度。10枚にしても+2,000円くらい。長くお世話になったp板.comさんには申し訳ないけど、価格が1/10では・・・
コロナの影響で少し時間がかかるそうですが、10日前後なので速いです。
ちなみこの基板、SPI入力のDMXドライバです。RaspberryPiからCSありのSPIを送るだけでレガシーDMXを8ユニバース出します。もちろんアイソレーションしてます。想定通りに動けば、ですけどね。
追記
価格は100x100mm以下なら1枚200円前後、50x50mm以下なら100円前後。感光基板で自作するより遥かに安い。試作段階でも気軽に使えます。
#電子工作
画像はKiCadによる完成イメージです。
本来ならブレッドボードなどで回路を隅々まで確認してから発注するべきですが、工程を一通り流し、仕上がりを確認するためのテスト発注です。
200x85mmと少し大きめの基板ですが、5枚で12,000円程度。10枚にしても+2,000円くらい。長くお世話になったp板.comさんには申し訳ないけど、価格が1/10では・・・
コロナの影響で少し時間がかかるそうですが、10日前後なので速いです。
ちなみこの基板、SPI入力のDMXドライバです。RaspberryPiからCSありのSPIを送るだけでレガシーDMXを8ユニバース出します。もちろんアイソレーションしてます。想定通りに動けば、ですけどね。
追記
価格は100x100mm以下なら1枚200円前後、50x50mm以下なら100円前後。感光基板で自作するより遥かに安い。試作段階でも気軽に使えます。
#電子工作
そんなワケでKiCadを使ってみたワケです。
慣れるとサクサク描けて良いCADだと思います。空き時間にユックリ習作しましたが思った通り描けます。
ただ、基板の寸法はインチ法とメートル法が混在するので、CAD云々以前にこの辺で混乱するかも。
#電子工作
慣れるとサクサク描けて良いCADだと思います。空き時間にユックリ習作しましたが思った通り描けます。
ただ、基板の寸法はインチ法とメートル法が混在するので、CAD云々以前にこの辺で混乱するかも。
#電子工作